2計算資料集之間的相似度(Top-down)#
以「類別資料」視角,運用Wikidata關鍵字的Property實現餘弦相似度推薦Depositar資料集#
有鑑於前案Bottom-up的運算時間過長(2小時多),本專案Top-down的目標便是「降低運算時長,仍能維持一定推薦品質」。
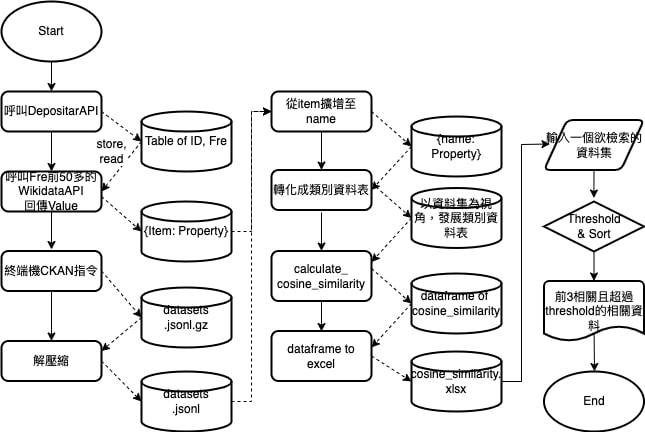
具體減少運算時長的實踐步驟,原本針對全部的Wikidata關鍵字進行運算「Propert、Value、en-label」。後來改成將Depositar前50常用詞彙的Property發展成類別資料的名目尺度編碼「有就是“1”,沒有就是“0”」。
如此便將原本運算的三個特徵,減少成一個;又將「全部462個item」改成「前50個(range(50))常用的item」,便大幅降低運算時間,6分鐘以內即可運算完成,可以開始進行資料集相互推薦服務。
除了上述前50個常用的item,我也實驗僅用前15個常用的item去發展推薦模式。在維持一定推薦品質的情況下,運算時長從6分鐘,更減少到1分鐘,便可以開始進行資料集相互推薦。
由此,帶來一些後續發展的靈感:1.要使用Propert、Value、en-label之一的那一個特徵,或者如何組合特徵,來發展推薦模式?2.需使用前幾常見的item發展類別資料編碼表?3.「Propert、Value、en-label」搭配前幾常用關鍵字發展的推薦模式組合,分別適合哪些需求的使用者?這些嘗試有待後續研究者實測了。