2計算資料集之間的相似度(Bottom-up)#
雙層社群網絡應用於Wikidata關鍵字發展Depositar資料集推薦系統#
在發展關鍵字的推薦之後,接著藉由「關鍵字的推薦模式」發展「資料集的推薦模式」。也就是說,這是一個Bottom-up建立起的推薦模式。
本專案開始之初(2023年8月7日),我先概要觀察Depositar資料集結構中帶有關鍵字的現況,只有505/1839=27%的資料有使用至少1個wikidata keywords描述資料集。而且505筆datasets中,更有294筆資料只是1~2個wikidata keywords用來描述該資料集。
由此看來,如何透過上述的含有少量wikidata的資料集來推薦其他資料集,這將是一個有趣的問題。
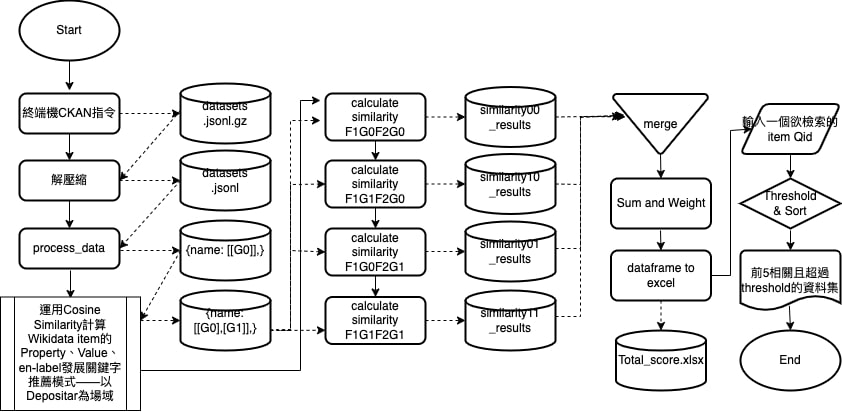
基於考量Depositar資料集關鍵字沒有很多(充分描述),所以我嘗試使用前例「運用Cosine Similarity計算Wikidata item的Property、Value、en-label發展關鍵字推薦模式——以Depositar為場域」將資料集舊有的Wikidata item(Generation 0)輸入進去,產生更多推薦關鍵字(Generation 1),再將兩文件(F1、F2)的兩代關鍵字(G0、G1)進行相似度運算,加總、加權以得到兩文件之間的相似度分數。
此專案Bottom-up建立起「關鍵字推薦模式」到「資料集推薦模式」,運用Wikidata特徵:從原本「Property、Value、en-label」提升至「Item」。並且僅透過Depositar內部Wikidata發展適合該資料平台資料集推薦模式。這樣的實現方法或許能落實在類似「企業內部(無法外網)封閉的電子化系統」。
然而,這種Bottom-up的模式需要大量時間運算每一個細節,才能完整建立期間模式。當前運算全部關鍵字、資料集相似度用時2~3小時,於是下一個專案發展的目標:降低運算時長,仍能維持一定推薦品質。